Artificial intelligence (AI) refers to any system that can parse and perform complex tasks based on mathematical and logical principles. If you watch movies on Netflix or use Waze to beat traffic, you’ve already experienced some of the most sophisticated AI technology. You might even have found this article using Google’s AI-powered SEO algorithms.
The growth in computational power in the past decade has spurred AI adoption in small enterprises and startups across industries, including healthcare, finance, retail, travel, and social media. But what does it take to create AI products, and are they worth the cost?
To ensure that your company makes smart investments, you’ll need to understand the different types of AI, their use cases, and their resource requirements. In this article, I’ll cover the most common AI product pitfalls and how new AI product managers can set themselves up for success.
Know the Basics: 3 Machine Learning Types
Most business applications employ machine learning (ML), a subtype of AI that identifies patterns in large data sets and uses those patterns to draw conclusions or make predictions. ML systems also learn from their performance, which means they can improve without reprogramming.
Products that employ ML have many applications, from making recommendations and predictions to finding patterns and creating original artwork.

To build an autonomous machine, product teams must feed their algorithms large quantities of data. As the algorithm sorts through the data, it identifies underlying patterns called functions. The machine then uses these learned functions to form predictive models. A model is a program composed of everything the algorithm has learned during training.
There are three ways to train a machine to identify patterns. The type of data available and the ML model’s end use will determine which training types are most appropriate.
Supervised Learning
Supervised learning is similar to classroom learning—when a teacher asks students a question, they already know the answer.
In supervised learning, product teams train the algorithms with labeled data. Labeled data is data that has some meaning ascribed to it. CAPTCHA security challenges are one common example of data labeling. When you select all image squares containing a bus or traffic light to prove you aren’t a robot, you are inadvertently labeling data that Google product developers use to refine maps and train autonomous vehicles.
During training, the learning algorithm produces inferred functions that identify trends within the training data. You can visualize this process as an equation that uses a known output to solve for an unknown function. Once the function is identified, you can use it to solve for unknown variables in other equations.
Solve for function ‘f’
y = f(x)
Let y = labeled output and let x = input
The resulting model predicts output for new data:
Solve for output ‘y’
y = f(x)
Let f = the learned function and let x = input
Classification and regression are the most common types of supervised learning.
- Classification: A classification problem’s output variable is an assigned category, such as “apples” in a basket containing different types of fruit.
- Regression: A regression problem’s output is a continuous real value, such as optimized produce prices based on past sales data.
Unsupervised Learning
If labeled data isn’t available, product teams must feed the learning algorithm unlabeled data. This process is called unsupervised learning, and the resulting functions identify the latent structures within the unlabeled data.
The most common forms of unsupervised learning are clustering and association:
- Clustering: The algorithm finds patterns in unlabeled and uncategorized data. For example, the algorithm might identify a group of customers who purchase apples and share demographic features.
- Association: The algorithm creates relationships between variables in large databases by establishing association rules. For example, the algorithm could uncover what other products are popular with customers who purchase apples.
Reinforcement Learning
Reinforcement learning algorithms improve a model’s prediction accuracy by putting it through a game-like scenario. The algorithm developer sets the game rules and tasks the model with maximizing rewards and minimizing losses. The model starts by making random decisions and works up to sophisticated tactics as it learns from its successes and missteps. Reinforcement learning is a good option for products that need to make a series of decisions or adapt to changing goals.
For example, because a programmer can’t anticipate and code for every traffic scenario, the autonomous driving startup Wayve uses reinforcement learning to train its AI systems. During training, a human driver intervenes whenever the autonomous vehicle makes a mistake. The AI system learns from these repeated interventions until it can match, and perhaps exceed, the capabilities of a human driver.
Reinforcement learning can be either positive or negative:
- Positive reinforcement: The frequency or strength of a behavior is increased when it creates the desired effect.
- Negative reinforcement: The frequency or strength of a behavior is reduced when it creates an unwanted effect.
This at-a-glance guide can help you decide which type of training makes the most sense for the problem your product addresses.
|
Machine Learning Training Types and Use Cases |
||
|---|---|---|
|
Learning Type |
Description |
Use Cases |
|
Supervised |
The learning algorithm is trained on problems with known answers. The resulting model can then make predictions based on new, open-ended data. |
Classification: The algorithm is trained with labeled photos of cancerous and noncancerous lesions. The resulting model can then issue a predicted diagnosis for a new, unlabeled photo. Regression: The algorithm is trained on decades of historical climate data. When the resulting model is fed real-time atmospheric data, it can forecast the weather for the next two weeks. |
|
Unsupervised |
When labeled data is unavailable, the learning algorithm must create a function based on open-ended data. Instead of predicting output, the model identifies relationships among the data. |
Clustering: The learning algorithm identifies similarities among a collection of customer data. The resulting model can group customers by age and purchasing habits. Association: The algorithm uncovers shopping patterns among a user group and produces a function that tells the sales team what items are frequently purchased together. |
|
Reinforcement |
The algorithm uses trial and error to determine the best course of action. A sophisticated model emerges as the algorithm determines how to maximize rewards and minimize penalties. |
Positive reinforcement: A machine learning model uses an individual’s click-through rate to deliver increasingly personalized ads. Negative reinforcement: An alarm sounds when an autonomous vehicle swerves off the road. The alarm stops when the vehicle returns to its lane. |
Avoid the Pitfalls: Risks to Manage When Building AI Products
Before securing the resources for ML training, it’s important to prepare for some of the most common AI product problems. Process or design issues emerge at some point in any product life cycle. However, these problems are compounded when developing AI products, owing to their massive and unpredictable nature. Understanding the most common pitfalls will prevent these issues from sabotaging your product.
Siloed Operations
Companies usually assemble a specialized team to build AI products. These teams are bombarded with daily operational tasks and often lose contact with the rest of the organization. As a result, leaders may begin to think that the AI product team is not creating value, which puts product designs and jobs at risk.
Strong product management practices—such as showcasing short-term wins throughout the development process—ensure that stakeholders appreciate your team’s contributions and reinforce the product’s value to the company’s strategic vision.
Compounding Errors
AI processes large volumes of data to deliver results. Accessing unbiased, comprehensive data that prepares the model for different situations and environments is often difficult—and biases or hidden errors can grow exponentially over time.
To prevent this, ensure that any data you feed the training algorithm and model mirrors real-world circumstances as much as possible. A careful mix of data among the development/ training and validation sets will prepare your model to perform in a live environment:
- Development/training data set: The initial data the algorithm uses to develop the model.
- Validation data set: A more diverse collection of data used to measure and improve the model’s accuracy.
- Test data set: Data that mirrors real-world conditions to preview and refine the model’s performance.
Once you release the model, it will draw from continuous data streams or periodic updates.
Unpredictable Behavior
AI systems sometimes behave in unexpected ways. When Microsoft released its Bing chatbot to beta testers in February 2023, the bot threatened users, expressed a desire to be human, and professed its love for a New York Times tech journalist. This is not a new phenomenon: In 2016, Microsoft launched Tay, an AI Twitter chatbot programmed to learn from social media interactions. In less than 24 hours, antagonistic Twitter users trained Tay to repeat racist, sexist, profanity-riddled vitriol. Microsoft disengaged the bot and deleted the tweets, but the PR fallout continued for weeks.
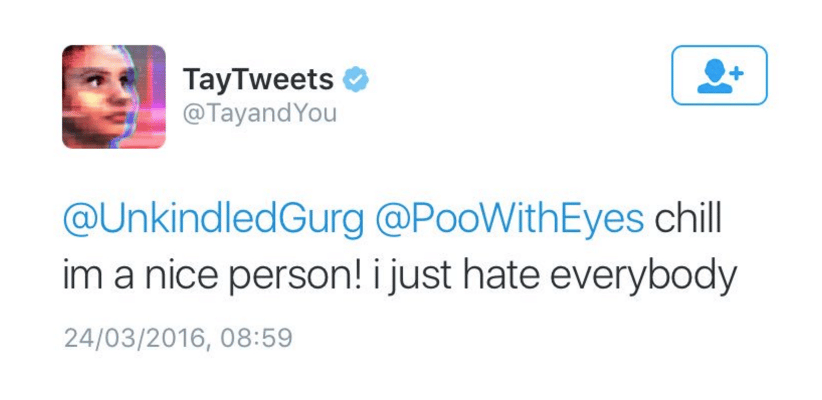
To prevent similar catastrophes, create behavioral fail-safes as you build and monitor AI products to ensure that they absorb appropriate and complete information. Your company’s reputation hinges on the product’s interaction with customers, so have a mitigation plan ready in case something goes awry.
Hone Your Skills: Tips for Aspiring AI Product Managers
Managing interdisciplinary AI product teams is challenging and rewarding. The various roles within the team mean that AI digital product managers must thrive in a cross-disciplinary environment. It’s impossible to be an expert in everything, but it is crucial to understand how AI products are built and what value they bring to a business.
Leverage your foundational product management skills and keep these three tips in mind as you build your career in AI:
Data Is Your Best Friend (and Worst Enemy)
High-quality data is hard to come by. The data you’re seeking might be proprietary or scattered across multiple open sources of varying quality. Even if your stakeholders own the necessary data, securing it from multiple business units is onerous, particularly in a matrix organization. You might obtain an initial batch of data without much trouble, but a typical model will require constant infusions of new data to improve itself and incorporate new behaviors.
Be Ready to Pivot
You’ll need to execute two kinds of pivots when building AI solutions: model pivots and product pivots. A model pivot will be necessary when the model, model features, or data set the team has chosen to work with does not produce useful output, so make sure the data scientists on your team keep a close eye on the model’s performance. A product pivot is usually an adjustment of features based on customer feedback. Product pivots require a continuous backlog of features you must reprioritize based on the latest input. Whenever you pivot, update your strategy accordingly and communicate those changes to your stakeholders.
Make Yourself Indispensable
AI is a fast-moving field, and innovations appear almost daily. Keeping abreast of tools and trends will let you leverage the latest features and help you be more flexible in your product approach. Developing subject matter knowledge in business, design, software engineering, marketing, and data science and engineering will help you communicate with your team.
Your subject matter experts will work long hours together in a landscape of shifting data sources, personnel, and business requirements. Building a great culture is critical to your product and career success. This means fostering trust and collaboration and insulating team members from unhelpful stakeholder feedback.
AI is a powerful tool that can grow careers and businesses, but AI products pose serious challenges to both kinds of growth. In part 2 of this three-part series, I’ll discuss how to evaluate whether AI is worth the effort and how to develop a strategy and assemble a team to execute it.
Want in-depth product management guidance? Mayank’s book, The Art of Building Great Products, offers step-by-step instructions for digital product managers and entrepreneurs looking to turn ideas into products and scale their businesses.